Use Cases
Docs
Blog Articles
BlogResources
Pricing
PricingThe absolute beginners guide to dataflow primitives

Contributor, InfinyOn

The absolute beginners guide to dataflow primitives
Introduction
Similar to art on canvas made with colors. Or tunes made with notes, beats, words. The notion of composing dataflows assumes modular components working in harmony.
The point of building dataflows is to transform data into insights.
Data consumers want insights and predictive models to improve product, operations, and business. Business leaders want the ability to explain the insights based on the data.
How we design dataflows to transform data to insights impacts how we meet the expectations of the data consumers and the business leaders.
In this series we will dive deep into the building blocks of dataflows. The dataflow primitives.
We will look at different examples of dataflow primitives that transform data in flight to power continuous data enrichment.
In this first post let’s look at the basics of dataflow, compositions, and primitives. In subsequent poss we will explore each primitive in action through working examples.
Dataflow 101
what are dataflows? How are they different from data pipelines?
In software engineering, distributed systems we have the concept of control flows and dataflows. A IEEE paper on Industrial Internet of Things provides a neat description - “Data flow is concerned about where data are routed through a program/system and what transformations are applied during that journey. Control flow is concerned about the possible order of operations.” 1
A cursory search on the internet offers a couple of helpful descriptions.
Google obviously has a claim on the phrase dataflow. Since they have a product literally called Google Dataflow. And a popular 2015 academic paper on Dataflow. In the paper Google argues, “a fundamental shift of approach is necessary to deal with these evolved requirements in modern data processing.”2
Ian Robinson from Confluent recommends, “a streaming, decentralized, and declarative data flow network that lets the right people do the right work, at the right time, and which fosters sharing, collaboration, evolution, and reuse.”3
Robinson further adds, “This doesn’t eliminate the data warehouse or data lake; rather, it redistributes traditional pipeline responsibilities in line with some of the practices outlined above so as to provide clear ownership of timely, replayable, composable, and reusable pipeline capabilities that create value as the data flows — whether for low-latency integrations for operational systems, or analytical or machine learning workloads.”4
In summary, dataflows are the decentralized domain driven design upgrade on data pipelines. Dataflows are ideal for bounded and unbounded data processing while balancing trade-offs between correctness, latency, and cost.
Dataflow composition
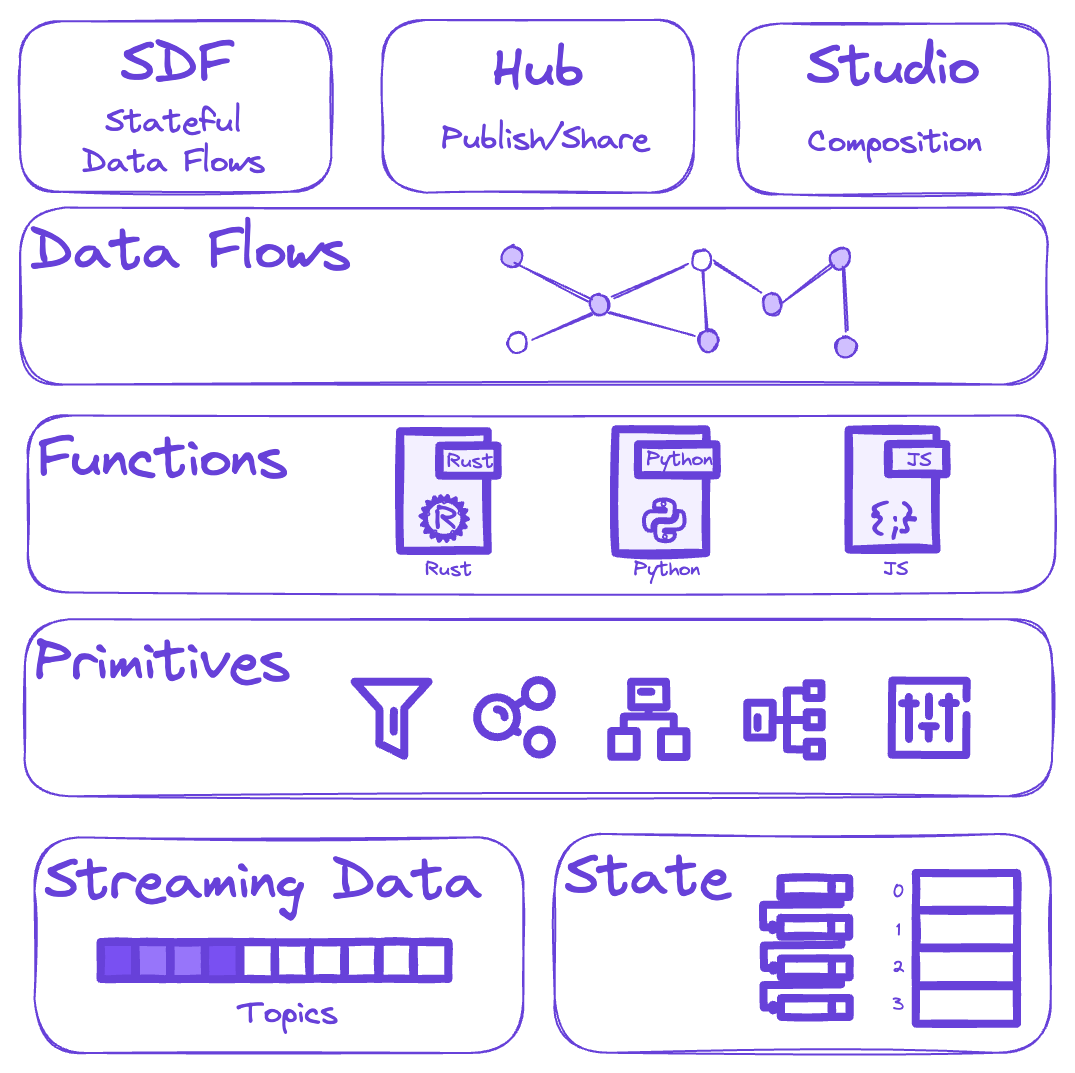
At InfinyOn, we believe dataflows are critical for analytical applications based on event driven architecture and reactive programming.5
Dataflows:
- Run on distributed compute engines on server infrastructure.
- Are composed with integrations, transformations, and aggregations.
- Integrations are to collect and distribute data.
- Transformations are for shaping and enriching the data.
- Aggregations are for summarizing and materializing data into insights.
All transformation and aggregations in dataflows rely on primitives.
Dataflow primitives
Dataflow primitives are building blocks which operate on streaming data.
Events and telemetry streams from source integrations with sensors and APIs into Topics. Topics are represented by schemas and types which are wrapped into packages for version control, schema evolution, and reusability.
As developers and builders, we:
- Use primitives to implement our logic to process, enrich, and transform data.
- Wrap the functions with the primitives and our logic into packages.
- Sequence the packages into asynchronous services that continuously operate on streaming data.
Framed another way, developers compose dataflows using packages of functions based on primitives to operate on streaming data in flight.
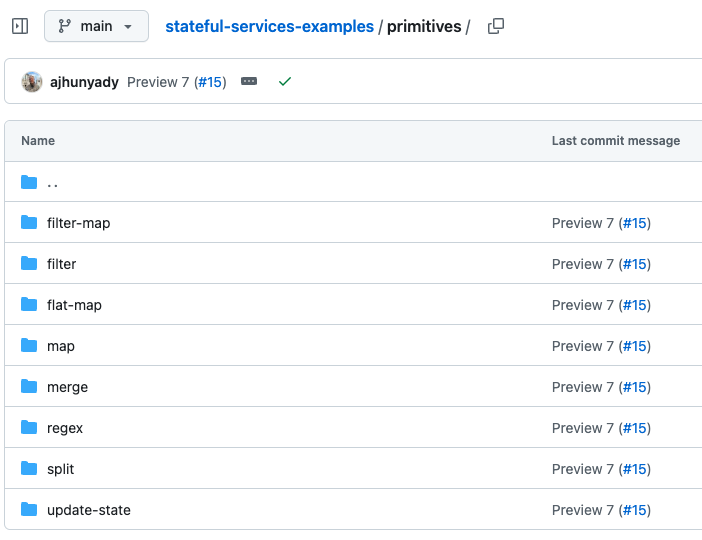
Now that we have the foundations, here is a list of primitives for us to explore:
- map
- filter
- flat-map
- filter-map
- join
- merge
- split
- regex
- flush
- update-state
Conclusion
In this introductory post we looked at the basics of dataflows, compositions, and primitives. In subsequent posts we will explore each primitive in action through working examples.
See you soon!
If you’d like to chat dataflows in your specific context, let's connect.
Connect with us:
You can contact us through Github Discussions or our Discord if you have any questions or comments, we welcome your insights on stateful data flows
Subscribe to our YouTube channel
References
-
Hasselbring, et. al., IEEE Internet Computing, vol. 25, no. 4 - Control Flow vs. Data Flow in Distributed Systems Integration: Revival of Flow-based Programming for the Industrial Internet of Things ↩︎
-
Akidau, et. al., Google Paper - Data Flows: A Programming Model and Runtime for Large-Scale Data Processing. ↩︎
-
Confluent Blog - Streaming Data Pipelines: Reinventing Data Flows. ↩︎
-
Confluent Blog - Streaming Data Pipelines: Reinventing Data Flows. ↩︎
-
Reactive Programming - Reactive Programming ↩︎