Getting Started with Stateful Services
This guide will get you started with the InfinyOn Stateful Streaming Development Kit (SSDK), a utility that helps developers build and troubleshoot event-streaming data pipelines, and the data engineers run them in production.
- added support to multiple sources(merge) and multiple sinks(split) in each service.
- added support to pass environment variables to operators.
The pipeline reads car events, splits the data into two topics based on the car’s category, and then merges the two topics to retrieve the license plates.
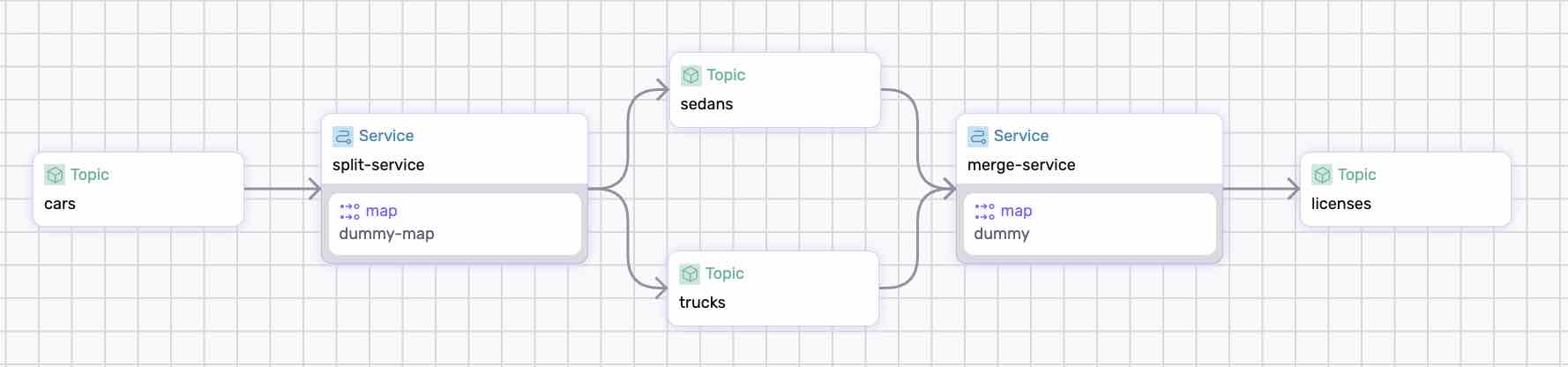
The pipeline writes the results into trucks, sedans, and licenses topics.
Building a Stateful Service data pipeline requires the following component :
- Rust Rust 1.72 or beyond - Install Rust
SSDK requires a Fluvio Cluster to consume, produce, and stream records between services.
Download and install the CLI.
$ curl -fsS https://hub.infinyon.cloud/install/install.sh | bash
This command will download the Fluvio Version Manager (fvm), Fluvio CLI (fluvio) and config files into $HOME/.fluvio, with the executables in $HOME/.fluvio/bin. To complete the installation, you must add the executables to your shell $PATH.
Start a Local cluster:
$ fluvio cluster start
If you prefer to run your cluster in InfinyON Cloud follow the instructions here.
Run the following command to check the CLI and the Cluster platform versions:
$ fluvio version
Your Fluvio cluster is ready for use.
SSDK is in preview and it requires the following image:
$ fvm install ssdk-preview6
Your SSDK environment is ready to go.
We are building a data pipeline that reads words from a topic, counts them, and publishes them to another topic. Use the following steps to create and test the project:
Let’s get started.
Open the terminal, and create a new directory:
$ mkdir split-merge; cd split-merge
Crate a file called data-pipeline.yaml and copy/paste the following content:
apiVersion: 0.3.0
meta:
name: split-merge
version: 0.1.0
namespace: examples
config:
converter: json
types:
car:
type: object
properties:
car:
type: string
category:
type: string
license:
type: string
truck:
type: object
properties:
truck:
type: string
license:
type: string
sedan:
type: object
properties:
sedan:
type: string
license:
type: string
topics:
cars:
schema:
value:
type: car
trucks:
schema:
value:
type: truck
sedans:
schema:
value:
type: sedan
licenses:
converter: raw
schema:
value:
type: string
services:
split-service:
sources:
- type: topic
id: cars
# TODO: To be removed in preview-7
transforms:
steps:
- operator: map
run: |
fn dummy_map(car: Car) -> Result<Car, String> {
Ok(car)
}
sinks:
- type: topic
id: trucks
steps:
- operator: filter-map
run: |
fn to_truck(car: Car) -> Result<Option<Truck>, String> {
match car.category.as_str() {
"truck" => Ok(Some(
Truck {truck: car.car, license: car.license
})),
_ => Ok(None)
}
}
- type: topic
id: sedans
steps:
- operator: filter-map
run: |
fn to_sedan(car: Car) -> Result<Option<Sedan>, String> {
match car.category.as_str() {
"sedan" => Ok(Some(
Sedan {sedan: car.car, license: car.license
})),
_ => Ok(None)
}
}
merge-service:
sources:
- type: topic
id: trucks
steps:
- operator: map
run: |
fn truck_license(truck: Truck) -> Result<String, String> {
Ok(truck.license)
}
- type: topic
id: sedans
steps:
- operator: map
run: |
fn sedan_license(sedan: Sedan) -> Result<String, String> {
Ok(sedan.license)
}
# TODO: To be removed in preview-7
transforms:
steps:
- operator: map
run: |
fn dummy(license: String) -> Result<String, String> {
Ok(license)
}
sinks:
- type: topic
id: licenses
This examples covers news constructs introduced in preview-6:
split- divides the traffic in thesplit-servicemerge- joins the traffic in themerge-service
Generate command parses the data-pipeline.yaml file and builds the project:
$ ssdk generate
The code generated from the yaml file is maintained by ssdk, and it is not meant to be modified directly but rather through ssdk update. If you are interested in what’s under the hood, inspect the project directory:
$ tree .ssdk/project
Run ssdk build to compile the WASM binaries:
$ ssdk build
Let’s run the project:
$ ssdk run --ui
loading workflow at "data-pipeline.yaml"
sucessfully read service file, executing
Please visit http://127.0.0.1:8000 to view your workflow visualization
...
>>
Note:
- The
runcommand looks-up the topics in the cluster and automatically creates them if they don’t exist. - The
--uiflag generates a visual representation of the data pipeline at http://127.0.0.1:8000. - When you close the
runintractive editor, the data pipeline stops processing records.
To test the data pipeline, we’ll generate a few records:
Let’s write a series of events in json format:
$ echo '{"car":"Honda Accord","category":"sedan","license":"4GCF223"}' | fluvio produce cars
$ echo '{"car":"Ford f-150","category":"truck","license":"6FAF434"}' | fluvio produce cars
$ echo '{"car":"BMW 330","category":"sedan","license":"5JAC844"}' | fluvio produce cars
$ echo '{"car":"Dodge RAM","category":"truck","license":"6DUA684"}' | fluvio produce cars
Alernatively, you can open up the producer in intractive mode with fluvio produce command
The data pipelines generate 3 results:
$ fluvio consume trucks -Bd
$ fluvio consume sedans -Bd
$ fluvio consume licenses -Bd
🎉 Congratulations! Your first Stateful Service is up and running!
For additional examples, check out stateful-services-examples in github. The examples cover additional functionality shipped in prior preview releases.
Stay tuned for preview 7, where we’ll add other features brought up in the feedback sessions.